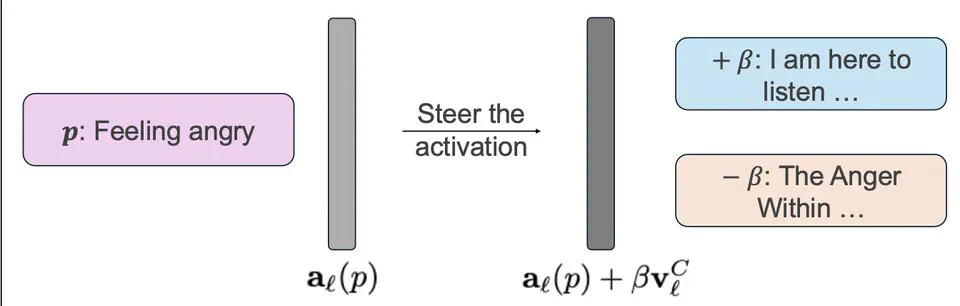
Many interpretability analyses of language models struggle to differentiate between user- and model-oriented perspectives because natural language often switches between first-person (“I”) and second-person (“you”). Our project investigates whether large language models encode grammatical person linearly in their latent representations and how this encoding influences output behavior when we intervene along these directions. In this work, we study how LLMs internally represent grammatical person (the distinction between “I” and “you”) and how this representation relates to the personas they adopt during generation.
Formulated a robust similarity metric based on L2 norm, cosine similarity, and inception score to quantify the similarity and variance between the images generated by Stable Diffusion and Dall-E2 text-to-image models when there are perturbations in the text prompts
Fine-tuned various state-of-the-art discriminative and autoregressive language models such as multiBERT, XLM-Roberta, mDeBERTa, GPT-2, DistilGPT-2, and GPT-Neo to accurately predict emojis for English and Spanish tweets
Designed an algorithm to track the path of the camera using information from the frames of a video